似た和歌を探せ
平安末期から鎌倉にかけての歌人、藤原定家に次のような和歌があります。
白妙の/衣ほすてふ/夏の来て/かきねもたわに/咲ける卯の花
「白妙の衣ほすてふ」といえば、すぐに思い浮かぶ歌がありませんか? そう、持統天皇の作とされる百人一首のあの歌です。
春過ぎて/夏来にけらし/白妙の/衣ほすてふ/天の香具山
定家の歌は、この持統天皇の歌を下敷きにして作られました。このように、よく知られた古い歌をもとにして新たに歌を作る方法を、本歌取りといいます。本歌取りは、そのもとになる古い歌を皆が知っていることを前提にしたものなので、それと知らずに新しい歌だけを見ても、表現の深みがまったく見えてきません。
そこで、計算機を使って、表現の「似た」歌の対を取り出すことを考えました。具体的には、二つの和歌集の間で、すべての組合せについて類似度を算出し、その値の高い対だけ人間が吟味する、という方法をとります。このようなアプローチでは、類似度をどう定めるかがポイントです。
似た文字列探し―従来手法
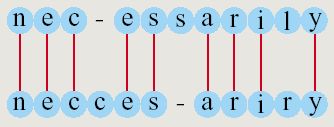
「似た」文字列探しには、「編集距離」という名の、非類似性を数量化する道具立てがよく用いられます。図1に編集距離について説明しておきましたので、関心のある方はごらん下さい。
編集距離は、スペルミスの半自動修正をはじめ、遺伝子情報処理における塩基配列やアミノ酸配列に対する相同配列探索などにも用いられています。しかし、編集距離は、あくまで打鍵ミスをモデル化して作られたもので、これをそのまま用いても和歌における表現の類似性はうまく捉えられません。
図1: 編集距離 たとえば、英単語necessarily をneccesariry と打ち間違えたとする。図において、直線で結ばれた2文字は文字の一致を、異なった2文字が上下向き合っているものは文字の置換を、一方がハイフンで他方が文字のものは、文字の挿入あるいは削除を表す。このことは、文字cを挿入し、文字sを削除し、文字lを文字rで置き換えれば、英単語necessarily をneccesariry へ変換できる、ということを意味している。このように、一方の文字列を他方の文字列に変換するには「挿入・削除・置換」が最低何回必要か、という観点から、二つの文字列間の非類似度を測ったものが編集距離である。この場合、編集距離は3となる。
似た文字列探し―新手法
もう一度、藤原定家の歌と、そのもととなった持統天皇の歌を比べてみましょう。持統天皇歌の第三・四句にあった「白妙の衣ほすてふ」は、定家の歌では場所が初句と第二句に動いています(図2参照)。また、第二句「夏来にけらし」は、少し姿を変えて「夏の来て」となり、第三句に現れています。このような句の順序の変化に対応するために、5!=5×4×3×2×1=120とおりの句の入れ替わりの一つ一つについて、句ごとに類似度の総和を求め、値の一番高いものを二首の類似度とします。
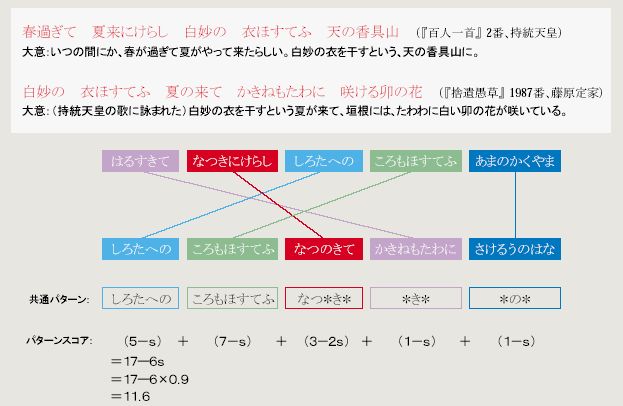
次に、句と句の間の類似度をどうするかですが、これは筆者らが新たに考案した「共通パターンとそのスコア」という図式に沿って定めました。詳細については図2をご覧ください。
この図式では、二つの文字列間の共通構造を、その両方に合致するパターン(共通パターン)としてモデル化し、共通パターンのもつスコア(重要度)の最大値を類似度と定めます。このパターンの種類を差し替えれば、様々な角度から類似性を考えることができます。筆者の研究グループは、類似メロディ探索などの研究も行っています。
図2: 類似度の計算 たとえば、二つの句「なつきにけらし」「なつのきて」は、いずれもパターン「なつ*き*」に合致する.ここで「*」はワイルドカードといい、任意の長さの任意の文字列で置き換えてよいものとする。そして、二つの文字列の両方に合致するパターンのうち、最もスコアの高いものを考え、その値を類似度とする。そのためには、各パターンにスコアをつける仕組みが必要だ。ここでは、パターン中の文字数を数え、連続した文字の塊の個数を0.9倍したものを引いた値をスコアとした。たとえば、「*なつ*」「なつ*き*」のスコアは、それぞれ、1.1、1.2となる。
計算機でみつけた類似歌
右に述べた方法を用いて、『古今集』『後撰集』という二つの勅撰集のあいだで類似歌抽出の実験を行ったところ、図3に示す歌の対が比較的上位に浮かび上がってきました。図の『後撰集』歌は、三十六歌仙のひとり、藤原兼輔の代表歌の一つです。兼輔は、『源氏物語』の作者として有名な紫式部の曽祖父としても知られています。この歌は「子を思う親の心情を直接的に表現した歌」として広く知られています。一方、『古今集』歌は、清原深養父(ふかやぶ)によるものです。こちらは、清少納言の曾祖父です。
図3: 計算機で発見した類似歌 この2首は並べてみると非常によく似ている。すなわち「人…/心は…に/あらねども/…/…るかな」という構造が共通している。さらに、2句目の「心は…に」の「…」の部分は「やみ/yami/」「かり/kari/」であって、母音がともに[a] [i] となっている点までが同じである。このようによく似た2首だが、これまで指摘がなかったのは、次のような理由によると思われる。通常、類似した和歌を探そうとする場合には、「闇」「迷ふ」などの名詞・動詞(自立語)に着目しがちで、それらをキーワードとして検索することになる。だが、上の2首に共通しているのは自立語ではなく、言い回しの部分である。言い回しは歌の情景などと直接には結びつかないため、記憶に残りにくい。したがって、これまで見過ごされてきたと考えられる。 さて、兼輔と深養父の間には交友関係があり、どうやら深養父の歌の方が先に詠まれたようです。兼輔の歌は、深養父の歌にある恋人への一途な愛情を、子を思う親心に仕立て直した歌ということになります。『後撰集』では、兼輔の歌は宴会で披露されたとあるから、恋心を親心に変容させた巧みな替え歌に宴席は盛り上がったことでしょう。替え歌としての知的技巧の面白みはやがて忘れられたけれども、子を思う親の情という歌の主題そのものが人々の共感を得て、よく知られる歌となったのでしょう。
また、これとは別に、類似した歌の発見が契機となって、歌集の成立年代を特定するという成果も得られました。成立年代不詳で鎌倉中期成立かと考えられていた『為忠集』が、実は室町時代に下る成立であると実証できました。四半世紀ぶりに新説を出したことになります。以上の研究は、同じ九大の人文科学研究院におられる南里(福田)智子先生と共同で行いました。

万物は文字列である?
ここでは、和歌を単なるかな文字の連鎖とみなし、表現の類似した歌をみつける方法をご紹介しました。塩基配列やアミノ酸配列の場合、人間が見ても、何が書いてあるかわからないので、単なる記号の連鎖とみなすことは自然な成り行きですが、同じような見方を、文学作品へ適用したことが、本研究の特徴といえます。
考えてみれば、テキスト情報はもちろん、音楽情報であれ、画像情報であれ、およそコンピュータで扱う情報は、記号の列、すなわち、文字列として表現されます。文字列は、単なる文字の連鎖であってこれ以上単純な構造はありません。したがって、文字列データを扱う技術は、計算機科学の最も重要な基礎技術の一つと言えます。そこで、筆者の研究グループでは、文字列処理に関する研究に力を注いでいます。あのピタゴラスは「万物は数である」と言ったそうですが、それにならえば「万物は文字列である」というところでしょうか。
